

In April 2020, we took part in the event of opening a Google Cloud region in Poland. Michał Zieniewicz, the Cloud Architect from Solwit talked to Michał Górski, a big data developer from Farmaprom. They were discussing technical details of the cloud solution implemented by Solwit and changes that cloud technologies brought to the company and its image among its clients.
Michał Zieniewicz, Solwit: Good morning and welcome to the session on real-time data analysis and the possibilities provided by BigQuery. My name is Michał Zieniewicz. I am the manager of the Cloud and Integration Services Business Unit in Solwit. I am responsible for developing the cloud portion of our organization and our employees’ cloud competencies. Solwit was founded exactly 10 years ago and since then we have always supported the cloud. We also develop and test business software, support our clients in the areas of artificial intelligence, analytics, data warehouses, and cloud environment optimization. We hire about 350 specialists, Google-certified architects and developers included.
Present with me today is Michał Górski from Farmaprom. Hi Michał.
Michał Górski, Farmaprom: Hi Michał. My name is Michał Górski and I work in Farmaprom as a Big Data developer. Our responsibility is to integrate multiple subjects in the Polish pharmaceutical market. These are pharmaceutical manufacturers, wholesalers, and pharmacies.
Michał Zieniewicz, Solwit: Ok, we have dealt with the formalities, we can move on to the topic of our meeting. Tell us… how did Farmaprom operate before its “Google era?”
Michał Górski, Farmaprom: Before we moved to the Google cloud we used to experience a lot of problems. As the company grew, new data sources were cropping up and it was difficult to integrate them. Frankly, we didn’t have a good way of linking the sources with each other.
Michał Zieniewicz, Solwit: What did you use all this data for?
Michał Górski, Farmaprom: We had two primary goals. One was to maintain a data warehouse for ourselves and for our clients. The second one was to provide our analytics department with tools making it possible to generate reports for clients and prepare market analyses.
Michał Zieniewicz, Solwit: Ok, Let’s start from the beginning. What data do you process in Farmaprom?
Michał Górski, Farmaprom: We have two kinds of data: sell-in information produced where the manufacturer, pharmaceutical wholesaler, and the pharmacy operations meet; and seel-out information produced from the client-pharmacy interaction when the receipt is realized.
Michał Zieniewicz, Solwit: Ok, let’s talk about the sell-in part. What does your ETL process look like?
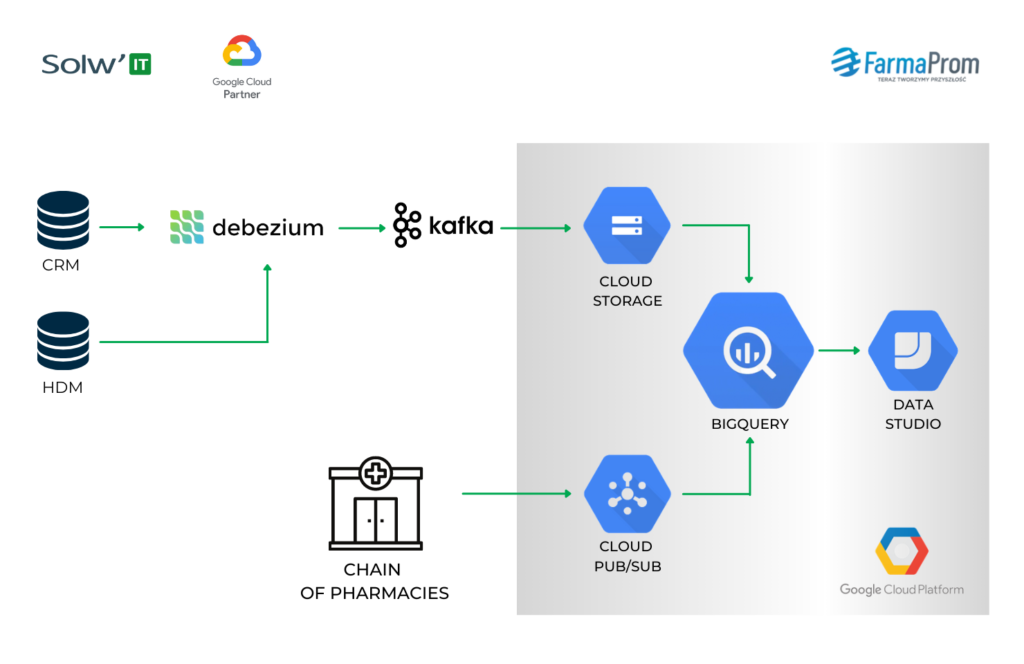
MG: We don’t have ETL. We have ELT. The data source is our CRM, which is a MySQL database. Debezium is responsible for Change Data Capture and the data flows directly to Kafka, using the topic-per-table scheme.
Michał Zieniewicz, Solwit: Why don’t you use Pub/Sub?
Michał Górski, Farmaprom: We started developing this pipeline a few years ago when Pub/Sub offered quite limited options. Data retention was no longer than a week if I remember correctly – after being read and ACKnowledged the data vanished from the subscription. Now it is much better but I guess retention is still monthly at best. Also, the data can be recovered now, but then it wan not possible. Finally, Debezium itself forced us to use Kafka.
Michał Zieniewicz, Solwit: So, let’s get back to the ELT process. How is data moved from Kafka to BigQuery?
Michał Górski, Farmaprom: Firstly, we use the schema registry in Kafka a lot. What schemes coming from our database we register is reflected by what tables appear in BigQuery. The data from Kafka is loaded to GCS, AVRO files are created and loaded to BigQuery, to proper tables. We upload those files quite often because the maximum delay between the CRM and the data warehouse is about 8 minutes. Partitioning is also thrown in, but we also partition data monthly. BigQuery allows daily partitioning, so we assign, for example, all the data that comes from September to Sept. 1st, and we don’t create too many partitions if there is not that much data in the table.
Michał Zieniewicz, Solwit: Why don’t you load it directly, but use GCS files instead?
Michał Górski, Farmaprom: Uploading is free and streaming is not. There are also no bandwidth limits when uploading. Streaming does have those limits and sometimes we bump into them. On the other hand, the eight-minute delay is acceptable in our business.
Michał Zieniewicz, Solwit: Alright, we have discussed the extract and load stages. But what about the third element of the process – transform.
Michał Górski, Farmaprom: We have this raw AVRO from Debezium loaded to BigQuery, to the right tables. This data is hard to analyze because there is information on what the record looked like before and after the change, and metadata regarding, e.g. the Binlog. These are not nice things to analyze. We use certain view layers to process this information. The first such view is history.
For example, if we have a table with orders which has changed multiple times and is now in 10 versions, we combine the tables imposing the most recent scheme. Seeing that the given key came on Monday, Wednesday, and Friday, we can calculate when the given record was valid in such and such version, using the Partition over lead lag function. We create the full table including the history of all its records and with such a view in place, we can define its conditions for the current point in time – we get the currently valid records only. We can also define it for those valid at midnight the day before so that the information flowing in does not change the reports. We can utilize partitioning and then limit the data, for example, to the two recent years. Not every analysis needs to go back as far as 15 years. So we save some costs. We have about ten such view setups, maybe more than a dozen, and they allow our analysts to review the data the way they find the most convenient.
Michał Zieniewicz, Solwit: It all sounds pretty complicated. Have you had any problems with it?
Michał Górski, Farmaprom: Yes, we used to have one problem with this solution. When the query is too complex for BigQuery, it will not be executed. And sometimes the analysts wrote querries for these views and every such view, a table, is under union (multiple table versions). It is not a matter of the amount of data, but the complexity of the query – the “query too complex” error.
So, to handle this problem we perform manual materialization of the views, that is merging them to the most recent version. Moreover, we add the incoming data on the fly, so we don’t have ten versions stuck together, but one snapshot and whatever has come in since its creation.
Michał Zieniewicz, Solwit: That’s clever. And tell me, is it the only pipeline in the sell-in data?
Michał Górski, Farmaprom: No, we have more, for example, the HDM data describing the doctor information. But the way they work is quite similar in all cases.
Michał Zieniewicz, Solwit: And what about the sell-out data? Are they different? Are they processed differently?
Michał Górski, Farmaprom: Yes. This pipeline is newer, so we have decided to use Pub/Sub. On the one hand, the source is MS SQL, and on the other, it is directly the software employed in apothecaries. So there’s no need to use Debezium, which, again, would force us to use Kafka. Besides, Pub/Sub has just increased data retention.
Beyond that, the way the pipeline works is similar, because we read data from the subscription itself and use it to build a file, also on GCS. When we know that the file is ready and everything has been saved properly and the data may be uploaded, we ACKnowledge it in Pub/Sub and confirm its reception. Pub/Sub gives us 600 seconds to do so, so in theory, the delay should be no more than ten minutes. Even if we cross this threshold, it is not a problem – we can read this again. But it virtually never happens.
Michał Zieniewicz, Solwit: Right. Now all your data is in BigQuery. What next?
Michał Górski, Farmaprom: First, we can share it with our analytics team to generate reports for our clients. Secondly, we use Click House as a sort of a front for BigQuery. BigQuery calculates data marts, which we load directly to Click House. This is the basic analytics for our clients: budget usage and plan realization.
What is more, the most important thing is the goal – the dedicated data warehouse. Every client can say: “I would like to have a data warehouse” and we actually create this warehouse for them. In the past, we used Oracle Business Intelligence, but our clients used to tell us that they didn’t want our BI and preferred raw data. These clients were large pharmaceutical companies and had their own BIs, sometimes more than one per company, so they didn’t need more. We wanted to meet their expectations, so we tested Spark. Calculating a basic sales mart took Spark about 14 hours. And it wasn’t Spark installed on my laptop, it was a cluster of ten solid computers. Not a big one, but still a cluster. Later we uploaded the data to BigQuery and the 14 hours turned into three minutes.
Michał Zieniewicz, Solwit: An amazing result.
Michał Górski, Farmaprom: Yes, this was the ultimate argument, so now we create such projects for our clients. Everyone who wants to have a data warehouse gets a separate GCP project, all the required data is uploaded and integrated. To show our clients this solution’s capabilities we also started creating Data Studio dashboards. At that point, our clients’ views on Oracle changed drastically. Everyone who was using or testing our solutions wanted to have our dashboards. Today, our clients don’t say “we want no BI, no additional visual layer,” they say “give us dashboards, give us Data Studio.”
Michał Zieniewicz, Solwit: It shows how technology changes the client’s perspective regarding data. Amazing. Does this approach towards data warehouse result in any problems?
Michał Górski, Farmaprom: Yes, it does, because every time a client declares they want to use Data Studio dashboards, we inform them that it requires Google accounts. Usually, at that point, the Polish branch calls the IT headquarters of the company and requests such accounts. And the answer is always the same – no way. Then we come in and try to solve the problem and explain what needs to be done. We also test different solutions, such as Superset, which can eliminate the need for Google accounts. We have tested Data Studio connectors and logging via service accounts, not to create new ones. Currently, we are verifying what Workforce can offer us, and maybe together with Data Studio embedding on our part, it will prove a good solution. Long story short – Google accounts for our clients are going to be created but on the fly. There are several solutions, we will certainly choose what works best.
Michał Zieniewicz, Solwit: Has the fact, that your data is processed so fast opened any new business opportunities? Does this technology allow you to do anything you couldn’t do before?
Michał Górski, Farmaprom: Oh, there are a lot of such examples. Let’s take shopping carts (the information from prescription receipts. Before, their analysis was very limited, both quantity and time-wise. It took several hours of our MS SQL 32-core server’s work.
Michał Zieniewicz, Solwit: It wasn’t just any server was it?
Michał Górski, Farmaprom: Right, but still, BigQuery does a thorough analysis of the shopping carts in a matter of seconds.
Michał Zieniewicz, Solwit: You could say it is done in real-time. Seconds compared hours – that’s what I call improvement.
Michał Górski, Farmaprom: There is also an interesting bonus we have got from this whole Google cloud experiment. Working with it was so enjoyable that we have just finished migrating our entire infrastructure. Now it is not only our BigData division that works in the cloud, but the whole Farmaprom.
Michał Zieniewicz, Solwit: 100% in the cloud! Awesome.
Michał Górski, Farmaprom: Yes, it is.
Michał Zieniewicz, Solwit: Ok, to sum up: Google technologies allow Farmaprom to realize their business goals, the current as well as the future ones, and as a bonus it helped you to develop and learn about new possibilities introduced by new technologies.


