

TABLE OF CONTENTS:
When this article was written, we didn’t know yet that in January 2023 TIOBE will choose C++ as the language of the year 2022! We had a nose! 🙂
In part one of this series on the most popular programming languages, we focused on the C# language. It ranked fifth in the July TIOBE 2022 index. Four months have passed, and the top five positions of the index remain unchanged – no surprises there; each language has retained its podium position.1
Today we will focus on two more items from the bottom of TIOBE’s distinguished top five, excluding Java2. This article covers the major differences between C and C++, the two languages that have topped the index since 2001.
It is unfortunately common for candidates we encounter during interviews to combine these two languages under one heading – C/C++. Since I verify technology knowledge during meetings, this signals that the candidate may not fully grasp the differences between these languages – I tend to suspect that it is only about C++. Hence I check it every time. It wouldn’t make sense for a C programmer to group that language with its successor3. As a matter of fact, they differ both in the way they work as well as in the projects in which we use them.
C is the most distinctive language of the five mentioned above. It is the only low-level language that significantly affects the areas in which it has practical applications. Although it is a procedural programming language, it can also be programmed functionally or using Object-Oriented Programming (OOP) practices. Keep in mind, though, that the programming language itself does not contain grammatical constructs to help you do so.
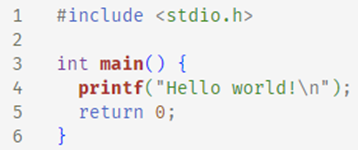
The C language is typically used whenever performance is at stake. It does not contain mechanisms such as polymorphism, memory management, memory access protection, or type control4. The absence of these mechanisms speeds up the program considerably but simultaneously places a lot of responsibility on the programmer – they have to ensure everything is under control.
The second major factor favoring this language is direct access to resources. The lack of mechanisms that limit the programmer’s freedom means that, in C, it is possible to easily and efficiently manipulate flags in processor registers, make direct entries into various areas of memory or manipulate communication with the components of the device on which we are working.
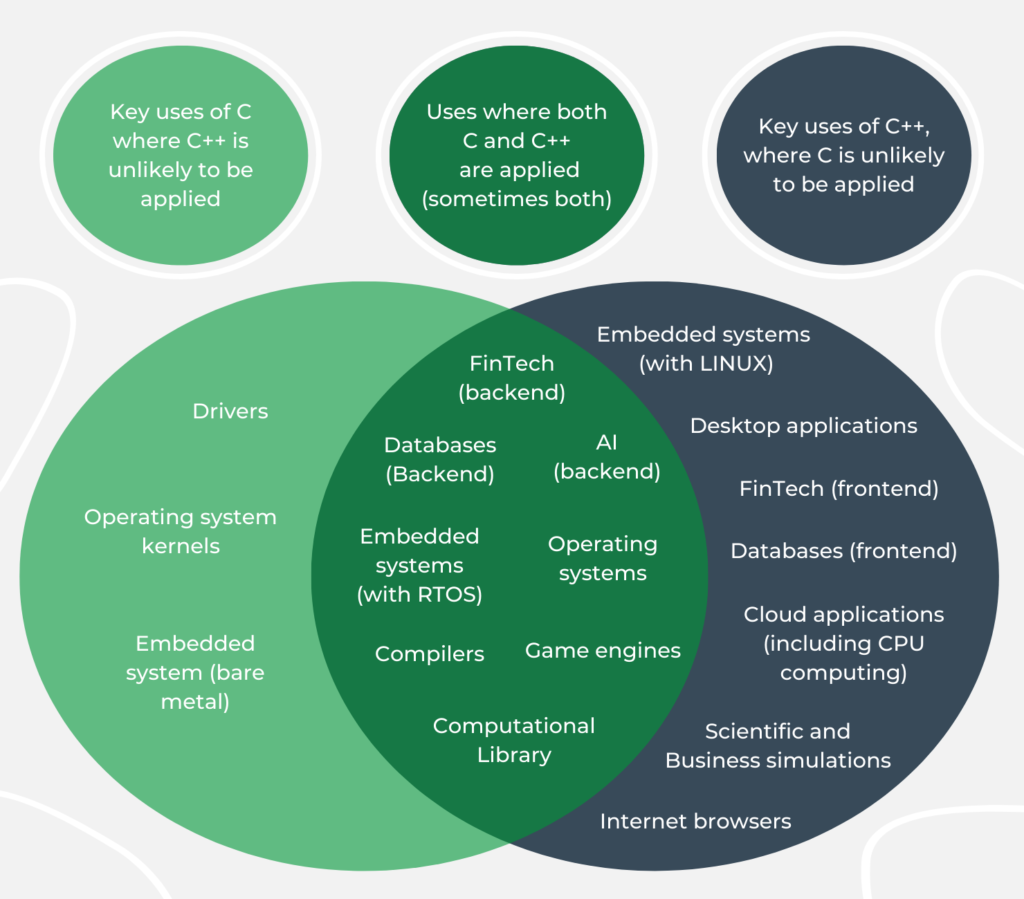
This freedom and efficiency are why drivers, operating system kernels, web browser kernels, the foundations of databases, graphical interfaces or game engines, and the vast majority of embedded software are written in C. What’s more, a C programming language is often used to write the lowest layers of software.
The grammar of the C language is very simple. It is pretty easy to write code in C that carries out complex mechanics, and that will compile without errors – and even if they occur, they are usually fixable in a few moments. Unfortunately, the apparent simplicity also means that few things are guaranteed in advance or checked at the compilation stage – it is very easy to make hard-to-find errors in this language that are usually unthinkable in modern programming languages. Moving from a high-level language to C requires you to discard many existing habits and build many new ones.


Although C’s syntax can be learned quickly, it is one of the most challenging programming languages to work with in the real world. Freedom of implementation makes it difficult to standardize a particular approach to solving problems. In projects written in C, programmers repeatedly reinvent the wheel5, contrary to the practice of code reuse. Such a wheel always looks slightly different from the previous one and requires separate tests. If several teams are working on a single product, this is very likely to happen6.
On top of that, having a magic trick in the form of macros, through which code can be generated on the spot, allows complex and difficult-to-understand codes to be easily created. Hence, it is not surprising that one team may not want to use the code of another collaborating team.
It is worth noting that much of the code written in programming language C, due to optimization and adaptation to a designated platform, is only intended for one specific application. However, proper separation into layers and components could make some of this code reusable. It is an approach I have used many times in the projects I’ve worked on. Sadly, this approach is uncommon in my experience.
When working at the lowest layer of software, any bug can turn out to be critical. In addition, a single hole may have global consequences when it comes to security issues7.
In embedded software, on the other hand, where updates are distributed over hundreds of thousands or millions of pieces of hardware, one critical error can even cause devices to stop working altogether8. It is no secret that anyone who has implemented Over-The-Air Update (OTAU) at least once is familiar with the vast number of factors involved, the delicate nature of the process, and the ease of making mistakes. It is pretty easy to overlook a mistake or forget a scenario when setting up an OTAU system. This is because several safeguards have to be implemented, and critical scenarios have to be handled complexly. In some cases, this mistake may result in permanent damage to the equipment, which then requires repair or replacement.
It is somewhat of a paradox that such a dangerous language as C is being used for such critical tasks. I am not surprised, however, by the growing popularity of Rust9 among programmers, whose design seems to be the inverse of the C language grammar – it severely restricts the programmer’s freedom, protecting code from many critical problems while giving almost identical performance and low-level component and memory manipulation as C.
By far, C is the most brutal language I’ve had to work with, not because of the complexity of the language itself, but because of the problems that have to be solved with it and the need to protect large amounts of code from many errors manually. C language is a very basic tool, meaning it is tough to solve complex problems with it. The most significant difficulty in mastering it lies in creating safe solutions and avoiding errors. It requires a great deal of project discipline and careful analysis of the code, both your own and that of other team members.
C++ differs greatly from its predecessor in terms of its features. C++ is a high-level object-oriented language, although it allows low-level access to resources just like the C language. C++’s historical baggage, in the form of constructs from C, is both its strength and one of its biggest problems10. Nevertheless, this does not mean that one should write in C++ language in the same way that one writes in C. Quite the contrary, in fact.
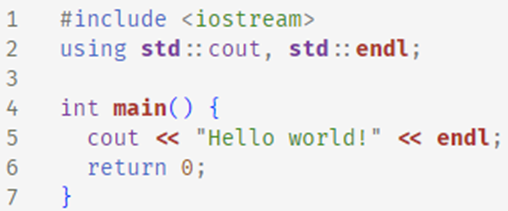
Libraries such as standard C++ and STL (Standard Template Library) provide a wealth of ready-made solutions, which in C had to be created from scratch. STL-related questions are frequently asked at job interviews for a reason – a thorough knowledge of the STL allows many basic problems to be solved quickly and efficiently. It addresses, among other things, memory management problems.
Since the entry of the C++11 standard, there has already been an increasing move away from the use of ‘pure pointers’ (raw pointers) from C, in favor of a range of available memory management mechanisms such as smart pointers. In terms of reflection, C++ still limps behind its newer rivals, but the most useful mechanisms, such as RTTI11 (run-time type information) and type traits, are there. On top of that, it handles exceptions12.
C++ programming language, like C, is used wherever performance counts because most mechanisms that slow it down are optional13. Hence, you can enjoy its many facilities with relatively low or no additional overhead. Thus, its applications are largely overlapping with those of C. Many new projects (including embedded systems) touching the lowest layer of hardware use both C and C++. It is popular specifically in embedded Linux devices.
The capabilities of this language allow it to be applied effectively in almost any field. It is possible to successfully develop desktop applications using platforms such as Qt. Modern C++ has a number of asynchronous programming mechanisms, including the task creation mechanisms found in the Event-based Asynchronous Pattern (EAP) or the mechanisms implementing the concepts of ‘future’ and ‘promise’ used in the Task-based Asynchronous Pattern (TAP). It is also widely used as a backend for many web services. C++ is a truly versatile language that will work well in any role but is obviously not the ideal choice for every project.
A significant issue when working on projects written in C++ language is managing the compilation process and additional packages. These are problems that are virtually non-existent in Python and marginally relevant in C#. Several external tools can be used to manage compilation – depending on what year the project was written; these can be Make, Autotools, or, more commonly nowadays, CMake. On the other hand, projects created in Visual Studio are usually compiled by the tools provided by the IDE. Managing external libraries requires using a package manager such as Conan14, which pairs well with the CMake tool. However, these are not tools that work reliably and give the same result in every project or on every platform. Working with them requires a bit of familiarity and experience, especially if you want to create your own package for use in other projects, whether proprietary or open-source. When working with code in C++ programming language, the compilation process cannot be disregarded. It even needs to be given quite a bit of attention, especially at key moments in the development of the project. This is especially true when extending the project with new modules, adding dependencies, implementing or changing the CI process, etc.
Despite the many improvements that help programmers in their work, C++ remains a difficult language. Its grammatical constructs often seem unnatural and require knowledge of the intricate mechanisms that run in the background to make the most of its power15.
Incomprehensible compilation errors, taking up tens of pages of text, are commonly encountered when working with templates. The example below is one of the simplest. In complex projects, looking for the correct error message takes a long time, and the IDE cannot always help with this.


However, compilation errors are the easiest to deal with, as they immediately come to the surface. Much trickier errors are those that, for instance, exclude RVO (Return-Value Optimization), ignore or incorrectly use move semantics, or one of the many advanced optimization mechanisms available in C++ language. It takes a lot of experience to recognize that a mechanism is not working correctly and to figure out why it is not performing. Moreover, the multitude of hidden mechanisms that occur “in the background” in various situations without informing the programmer makes it significantly more difficult for beginners to work with this language effectively. This is a programming language in which I have more than a decade of experience and yet, I have been frustrated more than once by its problems. Undeniably, C++ has the highest entry threshold of all programming languages nowadays, and requires years of experience to use it skilfully. As each updated edition16 introduces novel mechanisms that enrich the language, things are not made easier. These mechanisms often change the approach to certain concepts and require getting used to. For this reason, many projects choose to stop at a particular version of the C++ standard and not upgrade to a newer one17 – this is also the reason why it is so crucial to distinguish which version of the language a given programmer has only had contact with and which they have spent more time with.
The C and C++ languages, despite the enormity of their drawbacks, need not fear that they will lose their popularity in times to come – too much code has been written in them and still needs to be maintained. There are also new products being developed all the time for which they are best suited. Nevertheless, nowadays C and C++ are rarely chosen by novice programmers. This is simply because there are interesting job opportunities in competing languages that are much easier to learn and work effectively in less time. And yet, the popularity of these languages is constant, and so is the demand for C and C++ specialists. There will be no shortage of jobs for those who are not afraid of the challenges of learning these languages.
We have already covered C#, C++, and C. We will conclude the series with Python, a language that has little in common with the above three. However, its popularity has quickly pushed it to the top of the index. In 2018, it occupied only 3% of the market. Currently, it is around 17% – what makes it such a popular choice among programmers? The third part of the series will reveal all.
Let’s talk about your project! Our engineers will offer you the most suitable technical solutions to bring out the potential of your idea. Check out the projects we have completed for clients who needed custom software.



