

TABLE OF CONTENTS:
Zalety mikrokontrolera ESP32, zwłaszcza w dobie kryzysu półprzewodnikowego, wydają się bezdyskusyjne i sprawiają, że coraz częściej wybiera się go jako serce małych systemów wbudowanych. Ze względu na atuty, których część wymieniamy poniżej, platforma ESP32 stała się oczywistym wyborem dla jednego z naszych klientów. Pomogliśmy w opracowaniu urządzenia zbierającego dane z zewnętrznego przetwornika analogowo-cyfrowego z dostępem do danych przez Bluetooth Low Energy. W trakcie developmentu napotkaliśmy jednak na pewien problem, którego rozwiązaniem chcemy podzielić się w tym tekście. Niech wiedza idzie w świat!
ESP32 jest jednym z nielicznych, który utrzymał niską cenę oraz ciągłość dostaw. Oprócz dużej mocy obliczeniowej opartej o dwa rdzenie, pracujące z częstotliwością 240 MHz, posiada także transreceiver na pasmo 2.4 GHz, umożliwiający komunikację w standardach WiFi oraz Bluetooth. Dzięki swojej popularności SDK oferowane przez producenta dojrzało do stabilnej, dokładnie opisanej oraz dobrze przetestowanej wersji.
Kluczową funkcjonalnością urządzenia jest akwizycja danych z 16-bitowego przetwornika A/D podłączonego do mikrokontrolera ESP32 z użyciem interfejsu SPI. Ze względu na architekturę przetwornika konieczna jest oddzielna transmisja danych dla każdego z 16 kanałów po każdorazowej konwersji danych, a dodatkowym ograniczeniem jest maksymalna częstotliwość zegara SPI wynosząca 12 MHz. W naszym urządzeniu przetwarzanie danych odbywa się z częstotliwością 5 kHz, co daje nam 200 us pomiędzy kolejnymi seriami próbek.

O ile interfejs SPI zintegrowany w mikrokontrolerze ESP32 bardzo dobrze radzi sobie z przesyłaniem dużych pakietów danych, to w przypadku częstych, kilku bajtowych transmisji wypada gorzej, żeby nie powiedzieć bardzo źle. Problemem jest czas dostępu do modułu SPI w celu zainicjowania nowej transakcji.
Według dokumentacji producenta czasy transakcji dla jednego bajtu danych wynoszą dla różnych trybów odpowiednio:
| SPI mode | Execution time |
| Interrupt Transaction via DMA | 28 us |
| Interrupt Transaction via CPU | 25 us |
| Polling Transaction via DMA | 10 us |
| Polling Transaction via CPU | 8 us |
Dodatkowym ograniczeniem jest także zjawisko „Cache Miss”. Ze względu na to, że platforma ESP32 przechowuje kod programu w zewnętrznej pamięci Flash, producent zaleca skopiowanie procedur sterownika SPI do pamięci IRAM poprzez ustawienie flagi konfiguracyjnej CONFIG_SPI_MASTER_IN_IRAM w celu redukcji opóźnień wywołanych pobieraniem kodu z zewnętrznej pamięci. Aby zminimalizować czas pomiędzy transakcjami SPI, zastosowaliśmy metodę dostępu „Polling Transaction via CPU” oraz ustawiliśmy powyższą flagę.
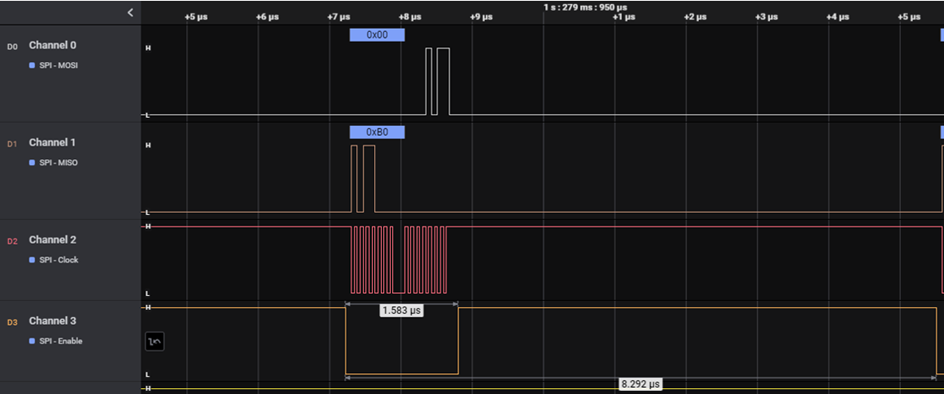
Rys 1.
Zmierzony czas transakcji dla jednego z 16 kanałów wyniósł odpowiednio:
Dla 16-kanałowego transferu wraz ze słowem konfiguracyjnym 9.9 us * (16 + 1) = 168.3 us. Przy okresie pomiędzy akwizycjami równym 200 us zostało nam zaledwie 31.7 us na obliczenia – niestety złożony algorytm obróbki i analizy danych, pomimo optymalizacji, nie mieścił się w czasie, jaki został nam po transmisji. Konieczna była optymalizacja transferu danych.
Zwiększenie częstotliwości zegara interfejsu nie wchodziło w grę ze względu na sprzętowe ograniczenia przetwornika A/D. Jedynym punktem do optymalizacji został czas dostępu do SPI, który zajmuje znacznie więcej niż sama akwizycja danych. Jednak skrócenie tego czasu nie było możliwe przy zastosowaniu sprzętowego interfejsu SPI. Dlatego postanowiliśmy rozwiązać ten problem inaczej.
Z pomocą przyszła nam stara, nie ciesząca się popularnością wśród programistów, metoda programowej implementacji interfejsu SPI. Dzięki niej pozbyliśmy się długiego czasu dostępu kosztem zmniejszenia zegara kluczującego dane, co koniec końców okazało się zaletą. Znacząco zmniejszyliśmy emisję promieniowaną przez linię CLOCK, co ułatwiło późniejsze przejście przez szereg badań kompatybilności elektromagnetycznej. Aby zapewnić koherentność danych, zastosowaliśmy odpowiednią synchronizację wątków i przemyślany podział zadań pomiędzy dwoma rdzeniami mikrokontrolera.
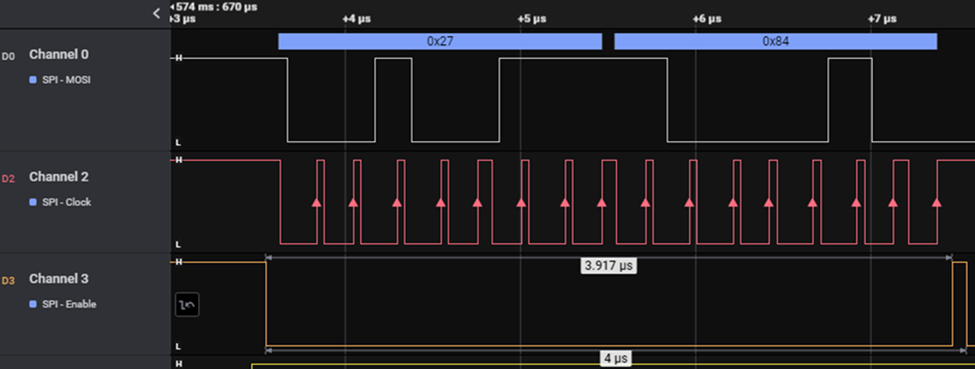
Rys 2.
Zmierzony czas transakcji dla jednego z 16 kanałów wyniósł odpowiednio:
Dla 16-kanałowego transferu wraz ze słowem konfiguracyjnym 4.083 us * (16 + 1) = 69.4 us. Skróciliśmy czas akwizycji danych o ok. 100 us, co dało nam 130.6 us na obliczenia, a więc umożliwiło nam bezproblemową implementację wszystkich funkcjonalności z dużym zapasem na rozwijanie algorytmów.
Jak widać niektóre metody, powszechnie uważane za nieprofesjonalne lub przestarzałe, w szczególnych przypadkach mogą okazać się jedynym rozwiązaniem. Warto zadbać także o odpowiedni proces tworzenia oprogramowania, w którym znajdzie się miejsce na szukanie twórczych i niestandardowych rozwiązań często nieprzewidzianych problemów




