

TABLE OF CONTENTS:
Metryki. Według jednych narzędzie uciemiężenia, według drugich „must have” dołączane do raportu dla Project Managera. Ale czy mogą one przynieść korzyść dla zespołu? Poniższe przykłady pokazują jak pomocne w ocenie jakości oprogramowania i procesu jego testowania jest śledzenie trendów wyników testów.
Mądrze zbierane metryki potrafią być bardzo przydatne w diagnozowaniu problemów z jakością aplikacji oraz funkcjonowaniem całego projektu czy zespołu.
Dlatego, jedną z podstawowych metryk, która powinna być stosowana w każdym projekcie, jest trend zmian wyników testów oprogramowania w projekcie.
Jej stosowanie nie wymaga dużych nakładów pracy, a pozwala zaobserwować zjawiska, które stają się widoczne, dopiero gdy spojrzy się na nie z perspektywy pewnego okresu. Poniżej kilka „z życia wziętych” przykładów wykorzystania takiej metryki (na podstawie wyników testów automatycznych) i problemów, których występowanie udało się wykazać, a ostatecznie rozwiązać.

Wersję releasową była wersja 1.95. Zaraz po niej nastąpił merge zmian deweloperów robionych na osobnym branch’u już dla przyszłego release’u wersji 2.x. Na te zmiany zupełnie nie był przygotowany dział testów co skończyło się test_error’em zdecydowanej większości testów automatycznych. Dodatkowo widać, że do wersji 1.3 włącznie, część defektów była „przykryta” przez wyniki test_error, co uniemożliwiło ich wcześniejsze wykrycie oraz naprawę.
Przyczyna: nieprawidłowa organizacja pracy między zespołem deweloperskim a testowym.
Efekt: niedziałające przez pewien czas testy automatyczne, późne wykrywanie dawno powstałych defektów.

Zjawisko stałej liczby wyników test_error.
Widać, że choć dla wersji 2.104 – 2.106 pojawiły się nowe błędy w testach automatycznych, to zostały one naprawione i liczba test_error’ów spadła do stałej liczby (10-20%).
Przyczyna: koncentracja zespołu na tworzeniu nowych testów i brak osoby odpowiedzialnej za nadzór nad napisanymi wcześniej i włączonymi do cyklu testowego.
Efekt: przyzwyczajenie się do sytuacji, że te testy nigdy nie przechodzą. Brak przetestowanych obszarów aplikacji z powodu niedziałających testów.
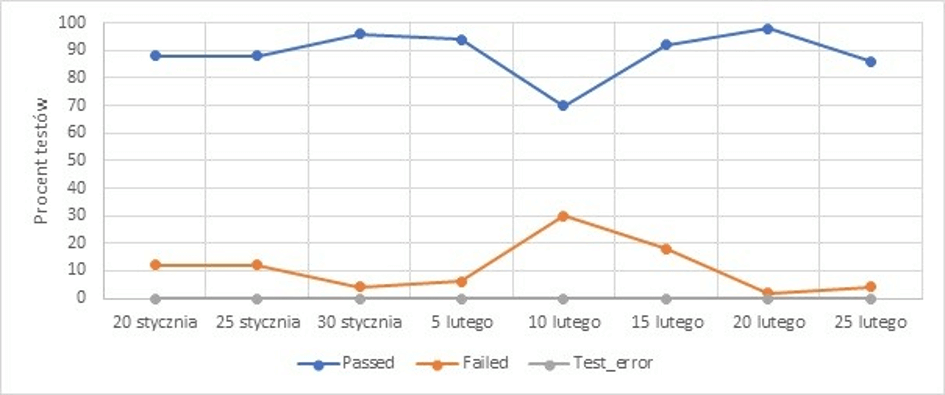
Przez ponad miesiąc nie pojawił się żaden test_error, pomimo wielu zmian dokonanych w tym czasie przez deweloperów. Jedyne testy „failed”, to te wynikające z defektów aplikacji.
Przyczyna: źle dopasowany obszar automatyzacji względem obszaru rozwoju aplikacji – zespół testowy tworzył testy automatyczne w innym obszarze niż ten, który był rozwijany przez zespół deweloperski.
Efekt: przekonanie o bardzo dobrym pokryciu obszarów aplikacji przez testy oraz o „samo – utrzymujących” się testach automatycznych.

Pojawiające się sporadycznie wyniki test_error są szybko naprawiane i ich ilość spada ponownie do 0. Liczba faili testów z powodu defektu w testowanym oprogramowaniu również w większości przypadków nie przekracza poziomu 10% co jest przeważnie akceptowalną wartością jeszcze przed release’m. Widać również sprawną reakcję działu testów na nagły wzrost liczby test_error’ów dla wersji 20.352 – .353, który naprawił nieprawidłowo działające testy. Na tym etapie nie zidentyfikowano żadnych istotnych problemów.
Oczywiście, w niektórych przypadkach sam trend wyników testów będzie niewystarczający, aby móc rzetelnie sformułować wnioski. Jednak umożliwia on szybkie zorientowanie się w ogólnej sytuacji i może wskazywać obszary procesu, które należy dodatkowo przeanalizować.




