

W kwietniu 2020 roku wzięliśmy udział w otwarciu regionu Google Cloud w Polsce. Michał Zieniewicz, Cloud Architect z Solwit, rozmawiał z Michałem Górskim, Big Data deweloperem z firmy Farmaprom. Dyskutowali m.in.: o szczegółach technicznych implementacji rozwiązania chmurowego dostarczonego przez Solwit oraz tym, jak usługi chmurowe zmieniły biznes i jego postrzeganie przez klientów.
Michał Zieniewicz, Solwit: Dzień dobry, witam was wszystkich na sesji, podczas której opowiemy o analizie danych w czasie rzeczywistym i o możliwościach, jakie daje nam BiqQuery. Nazywam się Michał Zieniewicz. Jestem Cloud Architektem w firmie Solwit. Odpowiadam za rozwój biznesu cloudowego i rozwój kompetencji chmurowych naszych pracowników. Firma Solwit powstała 10 lat temu i od 10 lat stawiamy na Cloud. Oprócz tego tworzymy systemy i aplikacje oraz testujemy oprogramowanie biznesowe, wspieramy naszych klientów w obszarach m.in.: sztucznej inteligencji, analityki i hurtowni danych i optymalizacji środowisk chmurowych. Solwit zatrudnia ok. 350 pracowników, w tym certyfikowanych przez Google architektów i deweloperów.
Jest ze mną Michał Górski z firmy Farmaprom. Cześć, Michale.
Michał Górski, Farmaprom: Cześć, Michał. Ja nazywam się Michał Górski. W Farmapromie jestem Big Data deweloperem. Zajmujemy się integracją podmiotów na polskim rynku farmaceutycznym. Są to producenci leków, hurtownie farmaceutyczne i apteki.
Michał Zieniewicz, Solwit: Okej. To formalności stało się zadość. Przejdźmy do tematu naszej prezentacji. Powiedz, w jaki sposób Farmaprom działał przed erą Google’a, tzn. przed korzystaniem z usług Google’owych.
Michał Górski, Farmaprom: Przed przejściem do chmury Google, mieliśmy sporo problemów, w miarę z rozwoju firmy pojawiały się nam kolejne źródła danych, które bardzo ciężko było integrować i tak naprawdę nie mieliśmy dobrego sposobu na to, żeby te różne źródła danych ze sobą łączyć.
Michał Zieniewicz, Solwit: A do czego chcieliście wykorzystywać te dane?
Michał Górski, Farmaprom: Mieliśmy dwa nadrzędne cele, jakie nam przyświecały. Jeden, to hurtownia danych dla nas i dla naszych klientów, a drugi to dostarczenie narzędzi naszemu działowi analiz – żeby mógł generować raporty dla klientów czy tworzyć analizy rynku.
Michał Zieniewicz, Solwit: Okej. To zacznijmy od początku. Jakie dane są przetwarzane przez Was w Farmapromie?
Michał Górski, Farmaprom: Mamy dwa rodzaje danych: dane sell-inowe – dane, które powstają na styku producenta leku, hurtowni farmaceutycznej i apteki i dane sell-outowe – to są dane, które powstają pomiędzy pacjentem a apteką w momencie realizacji recepty.
Michał Zieniewicz, Solwit: Okej, to zacznijmy od danych sell-in. Jak u Was wygląda proces ETL-owy?
Michał Górski, Farmaprom: Nie mamy ETL, a ELT. Źródłem danych jest nasz CRM. Jest to baza MySQL-owa. Za Change Data Capture odpowiada Debezium i dane płyną potem bezpośrednio do Kafki, korzystając ze schematu topic per tabela.
Michał Zieniewicz, Solwit: A dlaczego nie korzystacie z Pub/Suba?
Michał Górski, Farmaprom: Ten pipeline zaczęliśmy budować już kilka lat temu i Pub/Sub oferował wtedy dość ograniczone możliwości. Retencja danych była chyba maksymalnie tygodniowa. Dane po przeczytaniu, po “zaACKowaniu” znikały z subskrypcji. Teraz to wygląda dużo lepiej, ale retencja jest chyba maksymalnie miesięczna. Można też dane odtwarzać, ale wtedy takiej możliwości nie było. Ponadto, samo Debezium wymuszało na nas użycie Kafki.
Michał Zieniewicz, Solwit: Okej. To wróćmy do procesu ELT. Jak dane z Kafki trafiają do BigQuery?
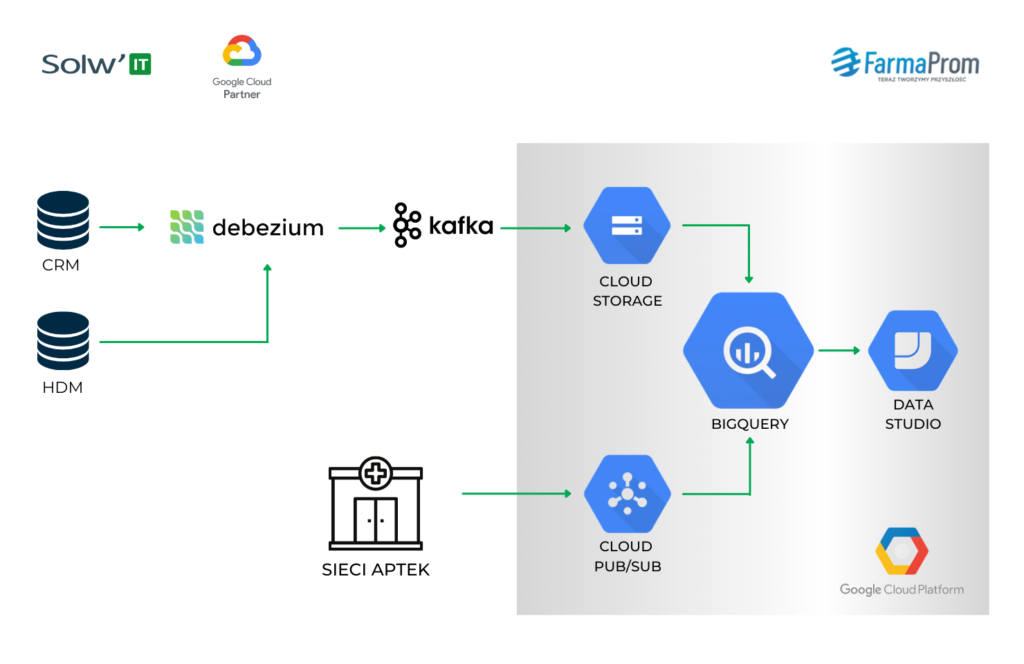
Michał Górski, Farmaprom: Po pierwsze, bardzo mocno posiłkujemy się schema registry w Kafce. To, jakie schematy płynące z naszej bazy danych zostaną zarejestrowane, to takie tabele odzwierciedlamy w BigQuery. Dane z Kafki zczytujemy na GCS-a, tworzymy pliki AVRO i ładujemy je do BigQuery, do odpowiednich tabel. Ładujemy te pliki dość często, bo maksymalne opóźnienie pomiędzy CRM a hurtownią danych to ok. 8 minut, a oprócz tego, dorzucamy tam jeszcze partycjonowanie. Często też partycjonujemy dane po miesiącach. BigQuery daje możliwość partycji po dniach, więc my, np. dla danych, które “wleciały” we wrześniu, przypisujemy zawsze 1 września i wtedy nie mnożymy wielu partycji, jeśli tych danych tak dużo w danej tabeli nie ma.
Michał Zieniewicz, Solwit: Dlaczego nie ładujecie tego bezpośrednio, tylko wykorzystujecie pliki na GCS-ie?
Michał Górski, Farmaprom: Ładowanie jest darmowe, a streaming płatny. Nie ma też limitu na to, ile danych można na sekundę załadować. W przypadku streamingu te limity są i czasami się od nich “odbijamy”. Z drugiej strony, opóźnienie od kilku do 8 minut jest akceptowalne biznesowo.
Michał Zieniewicz, Solwit: No dobrze, to mamy omówione: extract i load. Jak w waszym przypadku działa czy wygląda transform, czyli trzeci element całego procesu?
Michał Górski, Farmaprom: Mamy takie surowe AVRO z Debezium załadowane do BigQuery do odpowiednich tabel. Te dane są trudne dla analityków do analizowania, bo jest tam informacja o tym, jak rekord wyglądał wcześniej, i to jak wyglądał po zmianie oraz metadane odnośnie np. Binloga. Nie są to przystępne dane analityczne. My na te dane nakładamy sobie warstwy widoków, które te dane przetwarzają. Pierwszym takim widokiem jest history.
Jeśli np. mamy tabelę z zamówieniami, która zmieniła się kilkukrotnie i jest w 10 wersjach, to łączymy te wszystkie tabele, narzucając najnowszy schemat. Widząc, że dany klucz główny wszedł w poniedziałek, środę i piątek, używając funkcji Partition over lead lag, jesteśmy w stanie sobie wyliczyć, kiedy dany rekord w danej wersji obowiązywał. Tworzymy pełną tabelę z historią każdego rekordu i mając taki widok, możemy już np. nałożyć na niego warunki na moment obecny i dostajemy tylko rekordy, które są aktywne w tej chwili. Możemy też poprosić o te, które były aktywne o północy poprzedniego dnia, tak żeby dane, które spływają na bieżąco, nie zmieniały raportów.
Możemy skorzystać z partycjonowania. Wtedy możemy dane ograniczyć, np. do ostatnich dwóch lat. Nie każda analiza danych musi sięgać 15 lat wstecz. Wtedy oszczędzamy więc na kosztach. Takich zestawów widoków mamy około 10, być może kilkunastu i one pozwalają naszym analitykom dostać się do danych w taki sposób, jaki jest dla nich akurat najwygodniejszy.
Michał Zieniewicz, Solwit: Brzmi to dosyć skomplikowanie. Czy to rodzi jakieś problemy?
Michał Górski, Farmaprom: Tak, to rozwiązanie powodowało nam jeden problem. Jeśli analitycy do takich widoków piszą zapytania i każda taka tabelka – każdy taki widok jest pod spodem union (wielu wersji różnych tabel), to czasami dla BigQuery zapytanie zbyt złożone i go nie wykona. To nie chodzi o ilość danych, a o złożoność samego zapytania – błąd “query too complex”.
Więc my, żeby sobie z tym radzić, robimy ręczne materializowanie tych widoków, czyli scalanie ich do najnowszej wersji. Oprócz tego dodajemy na bieżąco te dane, które spływają i wtedy nie mamy “sklejonych” ze sobą 10 wersji, ale jeden snapshot i to, co spłynęło od momentu stworzenia tego snapshota.
Michał Zieniewicz, Solwit: Sprytnie. A powiedz, czy to jest jedyny pipeline w danych sell-in?
Michał Górski, Farmaprom: Nie, tych pipeline’ów mamy więcej, chociażby dane HDM-u, które opisują dane lekarskie. Jednak schemat działania tych innych pipeline’ów sell-inowych jest bardzo podobny.
Michał Zieniewicz, Solwit: Teraz przejdźmy do danych sell-out. To są inne dane? Inaczej przetwarzane?
Michał Górski, Farmaprom: Tak. To jest nowszy pipeline, więc zdecydowaliśmy się użyć Pub/Sub. Z jednej strony, źródłem danych jest MS SQL, a z drugiej bezpośrednio software w aptekach, więc nie ma potrzeby użycia Debezium, które wymuszałoby w pewien sposób Kafkę. Poza tym, Pub/Sub właśnie zwiększył retencję danych.
Schemat działania samego pipeline’a już później jest podobny, bo my zczytujemy dane z samej subskrypcji i budujemy z nich plik, też na GCS-ie. W momencie kiedy wiemy, że ten plik jest zbudowany, że się wszystko poprawnie zapisało i możemy te dane załadować, ACKujemy te dane w Pub/Subie, potwierdzamy ich odbiór. Na to Pub/Sub daje nam 600 sekund, czyli maksymalne opóźnienie teoretycznie może wynosić 10 minut. Nawet jeśli to przekroczymy, nic się nie stanie – możemy te dane zaczytać jeszcze raz, ale raczej do tego nie dochodzi.
Michał Zieniewicz, Solwit: No dobrze, teraz już macie wszystkie dane w BigQuery. Co się dalej z tym dzieje?
Michał Górski, Farmaprom: Po pierwsze, możemy je udostępnić naszemu działowi analiz, który może generować raporty dla klientów. Po drugie, używamy też Click House jako swego rodzaju frontu przed BigQuery. BigQuery przelicza data marty, które my ładujemy bezpośrednio do Click House. To jest podstawowa analityka dla naszych klientów: wykorzystanie budżetu i realizacja planów.
Poza tym najważniejszy jest cel – dedykowana hurtownia danych dla klientów. Każdy klient może powiedzieć: “chciałbym mieć hurtownię danych” i my tę hurtownię dla tych klientów tworzymy. Kiedyś używaliśmy Oracle Business Intelligence. Wtedy nasi klienci bardzo wyraźnie nam mówili, że oni nie chcą naszego BI i wolą surowe dane. Ci klienci to duże firmy farmaceutyczne. One już mają swoje BI-e, często więcej niż jeden, więc kolejny nie jest im potrzebny. My, chcąc sprostać temu, co słyszeliśmy od naszych klientów, testowaliśmy Sparka. Na Sparku przeliczenie takiego podstawowego martu sprzedażowego trwało 14 godzin. To nie był Spark na moim laptopie – to był nieduży cluster, ale jednak cluster 10-ciu dość solidnych maszyn. Potem załadowaliśmy te dane do BigQuery i z 14 godzin udało się nam obniżyć czas przeliczenia martu do 3 minut.
Michał Zieniewicz, Solwit: Super wynik.
Michał Górski, Farmaprom: Z takim argumentem już nie można dyskutować, więc dla klientów tworzymy obecnie takie projekty. Każdemu klientowi, który chce mieć hurtownię danych tworzymy osobny projekt w GCP, ładujemy dane, które dany klient ma widzieć oraz integrujemy je.
W celu pokazania klientom możliwości tego rozwiązania, zaczęliśmy też tworzyć dashboardy w Data Studio. W tamtym momencie, względem Oracle’a perspektywa naszych klientów zmieniła się diametralnie. Każdy z dotychczasowych klientów, czyli ok. kilkudziesięciu, którzy albo używają, albo testują, albo testowali nasze rozwiązania, chciał mieć dostęp do dashboardów. Obecnie klienci już nie mówią: “nie chcemy żadnego BI-a, żadnej wizualnej dodatkowej warstwy”. Wszyscy mówią: “chcemy dashboardy, chcemy Data Studio”.
Michał Zieniewicz, Solwit: Czyli to pokazuje, jak rozwiązania chmurowe zmieniają postrzeganie klientów, jeśli chodzi o dane. Super wynik.
A czy taki projekt, takie ustawianie hurtowni generuje też jakieś inne problemy?
Michał Górski, Farmaprom: Tak, generuje to trochę problemów, bo za każdym razem, jak klient deklaruje, że chce mieć dostęp do dashboardów w DataStudio, to my informujemy, że wymaga to kont Google. Najczęściej wtedy, polski oddział dzwoni do centrali IT danej firmy i przekazuje informację o zapotrzebowaniu na konta Google. Odpowiedź zawsze przychodzi jedna: “nie ma mowy”. Wtedy siadamy dopiero do stołu, tłumaczymy, co trzeba robić dalej. Próbujemy też ten problem rozwiązywać, testujemy różne rozwiązania: chociażby Superset, gdyż da się Supersetem wyeliminować potrzebę kont Google’owych. Testowaliśmy też konektory do Data Studio i próby logowania się tam przez service accounty, żeby nie musieć tworzyć kont Google. Teraz jeszcze weryfikujemy, co nam tak naprawdę daje Workforce. Być może jakaś kombinacja Workforce’a i tego co on oferuje razem z embeddowaniem Data Studio po naszej stronie będzie dobrym rozwiązaniem. Podsumowując, konta Google’owe będziemy tworzyć, ale w locie dla naszych klientów. Wyjść jest kilka. Któreś na pewno wybierzemy.
Michał Zieniewicz, Solwit: A czy to, że dane przetwarzają się teraz tak szybko, czy to pozwala Wam stworzyć nowe szanse biznesowe? Czy ta technologia pozwala Wam robić coś, czego wcześniej nie mogliście robić, z uwagi na ograniczenia technologiczne?
Michał Górski, Farmaprom: Takich przykładów jest naprawdę mnóstwo. Jeden, z nich to koszyki zakupowe. Wcześniej analiza koszyków zakupowych (koszyki zakupowe to informacje z paragonów recept w aptekach) możliwa była w bardzo ograniczonym zakresie. Ograniczonym zarówno ilościowo, jak i czasowo. To było kilka godzin na naszym serwerze MS SQLowym, który miał 32 core’y procesora.
Michał Zieniewicz, Solwit: Nie był to pierwszy lepszy serwer z brzegu.
Michał Górski, Farmaprom: Tak. BigQuery całościową analizę koszyków zakupowych wykonuje w dosłownie kilka sekund.
Michał Zieniewicz, Solwit: I to jest czas rzeczywisty praktycznie, bo sekundy w porównaniu do godzin – to jest zysk.
Michał Górski, Farmaprom: Poza tym, drugi ciekawy bonus z naszych eksperymentów z chmurą Google’ową jest taki, że tak dobrze nam się na niej działało, że niedawno zakończyliśmy migrację całej infrastruktury firmowej do chmury. Już nie tylko dział Big Data, ale cały Farmaprom jest w chmurze.
Michał Zieniewicz, Solwit: 100% w chmurze. Super.
Michał Górski, Farmaprom: Tak. Zgadza się.
Michał Zieniewicz, Solwit: Okej, to podsumowując: dzięki technologii Google Cloud w Farmapromie jesteśmy w stanie zrealizować nasze cele biznesowe, które zostają postawione, a dodatkowo, pozwala to na rozwinięcie się i poznanie nowych możliwości związanych z tą technologią.


